
0. Abstract
GPT, Bert와 같은 Large Language Model(LLM)을 Fine-tuning하는 것은 굉장히 효과적인 transfer mechanism이지만, fine-tuning은 많은 downstream task들에 대해 파라미터적으로 비효율적이다. (모든 테스크에 대해 항상 전체 모델을 다시 학습시켜야하기 때문이다. 즉, 모든 파라미터를 다시 학습시킨다.)
이에 대한 대안으로 논문 저자들은 adapter module을 통해 transfer하는 방법을 제시하고 있다. Adapter module은 compact하고 extensible한 모델을 생성할 수 있다. 각각의 의미는 다음과 같다.
- Compact Model: 작업마다 조금의 파라미터만을 추가해 문제를 해결하는 모델이다.
- Extensible Model: 이전 작업을 잊어버리지 않고 점진적으로 새로운 문제를 풀 수 있도록 훈련되는 모델이다.
논문 저자들은 BERT Transformer 모델을 transfer learning 시켜본 결과 다음과 같은 결과를 얻을 수 있었다고 한다.
- full fine-tuning 모델과 비교했을 때 0.4%이내의 성능 차이를 보였다.
- adapter module을 사용한 경우 각 테스크마다 3.6%의 파라미터를 추가했다.
반면 fine-tuning의 경우 각 테스크마다 100%의 파라미터를 학습했다.
1. Introduction
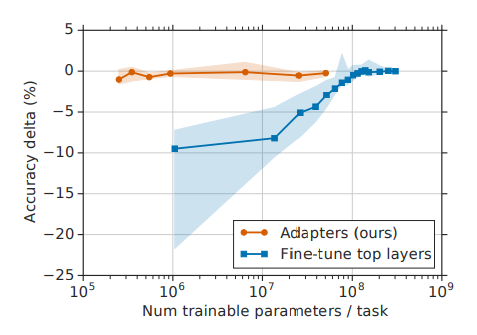
- y축은 정확도, x축은 학습가능한 파라미터의 숫자를 의미한다.
- 이 그래프는 adapter based tuning을 통해 적은 파라미터를 학습함에도 불구하고, full fine-tuning과 비슷한 성능을 달성할 수 있음을 의미한다.
위 그래프의 자세한 내용은 아래 챕터에서 다룰 예정이다. 어쨋든 논문 저자들은 adapter 모듈을 통해 달성할 Goal을 다음과 같이 설명한다.
- The goal is to build a system that performs well on all of them, but without training an entire new model for every new task.
즉, 새로운 테스크를 위해 항상 전체 모델을 학습시키지 않으며 이런 새로운 테스크들에 대해 잘 작동하는 시스템을 개발하는 것이 목표라고 한다. 테스크들 간에 높은 정도의 sharing은 (많은 양파라미터를 공유하는 것은) 클라우드 서비스와 같이 클라이언트로부터 다양한 요청(테스크)가 들어오는 application들에게 유용하다. 이를 위해 저자들은 compact하고 extensible한 downstream model을 생성할 수 있는 transfer learning 전략(=adapter tuning)을 제안한다.
기존 NLP에서 transfer learning 기술로 흔히 사용되던 것은 feature-based transfer과 fine tuning 방식이다.
- Feature-based transfer learning: Worde2Vec, Glove, ELMo 등의 모델을 활용한다. 해당 모델들은 단어의 임베딩 값(벡터)를 반환할 수 있다. 이러한 사전 학습된 임베딩 벡터들을 포함하도록 하는 방식이다.
- Fine-tuning: GPT 등의 모델을 활용한다. 사전 학습된 LLM을 가져와서 dwonstream task에 맞도록 파라미터를 튜닝하는 방식이다.
Fine-tuning은 Feature-based 방식에 비해 더 좋은 성능을 보여준다. 또한 Fine-tuning의 경우 테스크들 간에 network를 공유하는 경우 Feature-based 방식에 비해 더 parameter efficient하다. 하지만 현재 논문의 저자들이 제안하는 adapter tuning 방법은 더 parameter efficient하다고 한다.
또한 저자들은 Adapter-based tuning 방법을 multi-task learning와 continual learning에 비교한다. Multi-task learning은 compact model을 만들 수 있지만, 모든 테스크들에 대해 동시적 접근(simultaneous access)를 요구한다. (반면 adapter-based tuning은 그렇지 않다.) Continual learning system은 extensible model을 만들 수 있지만 다른 테스크들을 계속 학습하면 이전 테스크를 잊어먹는 문제가 있다. (adapter는 공유된 파라미터들을 frozen하기 때문에 문제가 없다.)
2. Adapter tuning for NLP
adpater tuning의 세 가지 key property는 다음과 같다.
- It attains good performance.
→ 좋은 성능을 가진다. - It permits training on tasks sequentially, that is, it does not require simultaneous access to all datasets.
→ 작업들을 순차적으로 학습시킨다. 따라서 모든 dataset의 동시적 접근을 요구하지 않는다. - It adds only a small number of additional parameters per task.
→ 각 테스크마다 적은 추가 파라미터를 추가한다.
위와 같은 property들은 만족시키기 위해 저자들을 bottlenect adapter module을 제안했다. vanilla fine-tuning은 network의 top layer 부분을 수정했다. 왜냐하면 기존 테스트(upstream task)와 적용하려는 테스크(downstream task)의 label space와 loss가 다르기 때문이다. 하지만 Adapter module은 좀 더 일반적인 architectural modification을 수행한다. 단지 기존 network에 새로운 layer를 삽입하며 기존 network의 파라미터는 변경되지 않는다. (단지 새로 추가된 adapter layer의 파라미터만 학습 중 변경되며, 해당 레이어는 처음에 랜덤하게 초기화된다.)
- 기존 fine-tuning은 새로운 top-layer와 기존 network의 파라미터 모두 학습시킨다. 반면 adapter tuning은 기존 network의 파라미터들은 frozen되기 때문에 많은 테스크들이 파라미터를 공유한다.
Adapter Module은 두 가지 주요 feature를 가진다.
- A small number of parameters.
→ 적은 수의 파라미터 - A near-identity initialization.
→ near-identity 초기화: 입력을 거의 그대로 출력하도록 초기화함을 의미한다.
adapter module은 기존 network layer들에 비해 상대적으로 적다. 이는 테스크가 추가되어도 모델의 사이즈는 상대적으로 느리게 증가된다는 의미다. 이 때문에 near-identity initialization이 안정적인 학습을 위해 요구된다고 한다. near-identity function을 통해 adapter를 초기화함으로써 기존 network는 학습을 시작할 때 영향을 덜 받는다. adapter와 관련된 사실에 대해 저자들이 발견한 것은 다음과 같다.
- 학습 중에 adapter는 전체 네트워크의 activation(활성화) 분포를 변경할 수 있다.
- adapter module 필요하지 않으면 무시될 수 있다.
- 몇 개의 adapter는 다른 adapter에 비해 네트워크에 더 영향을 미친다.
- 초기화가 identity function에 너무 많이 벗어나면 학습에 실패할 수 있다.
2.1. Instantiation for Transformer Network
저자들은 adapter module을 transformer에 적용했다.
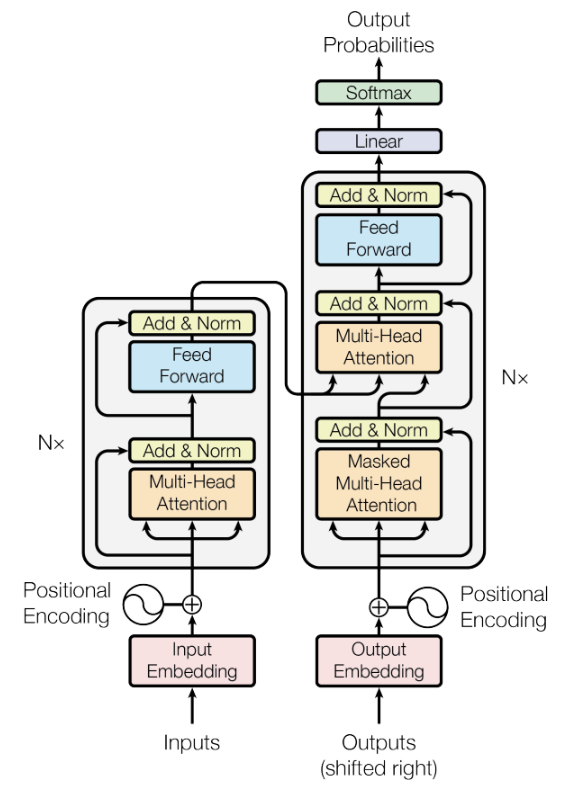
먼저 transformer의 구조를 살펴보자. transformer의 각 layer는 Feed-forward layer와 Attention layer 총 두 개의 주요 sub-layer가 존재한다. 각각의 sub-layer는 이후 이전 층의 출력과 이후 층의 입력의 사이즈를 맞추기 위해 바로 projection 연산을 수행한다. 이때 skip-connection도 적용되어 있음을 확인할 수 있다. 각 sub-layer의 출력은 layer normalization의 입력이 된다.
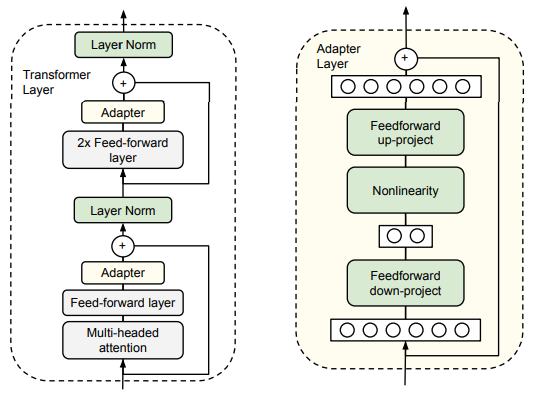
이때 저자들은 두 개의 adapter를 이 sub-layer들 이후에 삽입했다. 구조상 adapter는 sub-layer의 출력과 직접적으로 연결된다. (단, projection은 발생한 후고, skip connection은 발생하기 전에 추가되었다.) adapter의 출력은 이어지는 layer normalization에 입력된다.
이제 adapter의 구조를 살펴보자. 파라미터의 개수를 제한하기 위해 저자들은 bottlenect architecture를 제안했다. adapter는 원래의 d 차원의 feature를 더 작은 차원인 m 차원으로 nonlinearity(비선형)을 사용해 project하고 다시 d차원으로 project시킨다. 이때 layer당 추가되는 파라미터는 bias를 포함하여 2md+d+m이다. 이때 m<<d로 설정함으로써 task를 추가할 때 추가되는 파라미터의 수가 제한된다. (bottlenect 차원인 m은 performance와 parameter efficiency사이의 trade off를 적절히 조율하는 간단한 방법이다.) 이때 adapter module은 내부에 한 개의 skip-connection을 가진다. 이 skip-connection 덕분에 projection layer가 거의 0으로 초기화 되면 adapter module이 대략 identity function으로 초기화될 수 있다.
adapter moudle에 있는 layer들을 학습함과 동시에, 새로운 layer normalization parameter들도 같이 학습된다. 이 normalization layer는 2d개의 파리미터만을 통해 parameter efficient adaptation을 생산할 수 있다고 한다. (파라미터 효율적인 adaptor를 만들 수 있다는 것 같다.) 하지만, 이 레이어틀 따로 혼자서 학습시킨 경우 좋지 못한 성능을 보였다고 한다.
3. Experiences
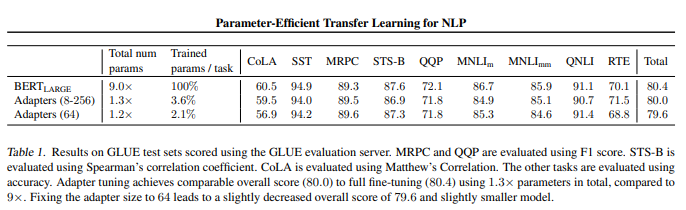
GLUE benchmark에서 Adapter는 평균적으로 80.0점, Full fine-tuning은 80.4점을 얻었다. 다른 task의 결과는 논문을 참고하자.
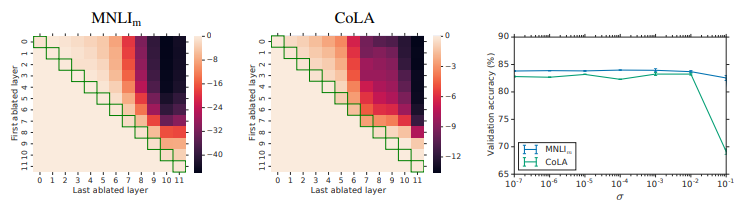
논문에서는 Adapter의 영향력이 어느 정도인지 히트맵을 통해 설명한다. x축은 마지막으로 제거된 layer, y축은 처음에 제거된 layer를 의미한다. 녹색으로된 영역은 단일 영역만 제거된 것으로 최대 2%정도 정확도가 감소했다. 반면 모든 Adapter가 제거된 경우 MNLI는 37%, CoLA는 69%가 감소했다. 즉, Adapter 하나가 제거된 것은 전체 네트워크에 적은 영향을 주지만, 더 많은 Adapter가 제거될수록 영향이 크다는 것을 알 수 있다.
또한 대각선에서 멀어지는 경우 더 많은 계층이 제거됨을 의미하는데, 0~4층을 제거해도 영향이 거의 없는 것을 확인할 수 있다. 반면 높은 층을 여러 개 제거하는 경우 영향이 큼을 확인할 수 있다. 즉, Higher Layer의 Adapter가 Lower Layer의 Adapter보다 더 영향이 크다는 사실을 알 수 있다.
출처
논문: https://arxiv.org/pdf/1902.00751
'AI > NLP' 카테고리의 다른 글
| [논문 리뷰] Prefix-Tuning: Optimizing Continuous Prompts for Generation (0) | 2024.05.03 |
|---|---|
| [논문 리뷰] LoRA: Low-Rank Adaptation of Large Language Models (0) | 2024.05.01 |
| Parameter Efficient Fine-Tuning (PEFT)란? (0) | 2024.04.30 |